Event Sourcing and CQRS

In a previous post, I described the following pattern: CQRS (https://marc-architect.hashnode.dev/cqrs-pattern).
Now, I'm going to write about event-sourcing and how it can fit well with CQRS.
Event-sourcing purpose is to persist an object as the sum of all its states.
Instead of storing an object state at a point in time, we will store all the object states change events and deduce the current state as the sum of all the events:
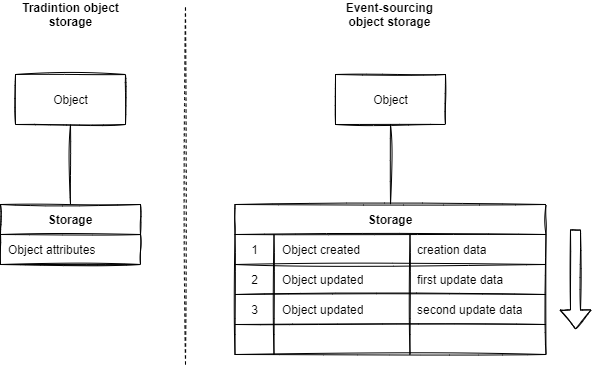
On the left, you always have the last state of the object.
On the right, you need to compute all the states of the object, from the first to the last, to get the current state.
This is event-sourcing and now I'm going to explain why it fits well with CQRS.
I remind that CQRS pattern purpose is to separate (segregate) the reads from the create/update/delete operations to the object (aka. aggregate).
The create/update/delete operations to the object will follow the event-sourcing pattern just described above.
The reads operations will be directed to a view built upon the events and maintaining the object current state (or any other previous state btw).
See the schema below:
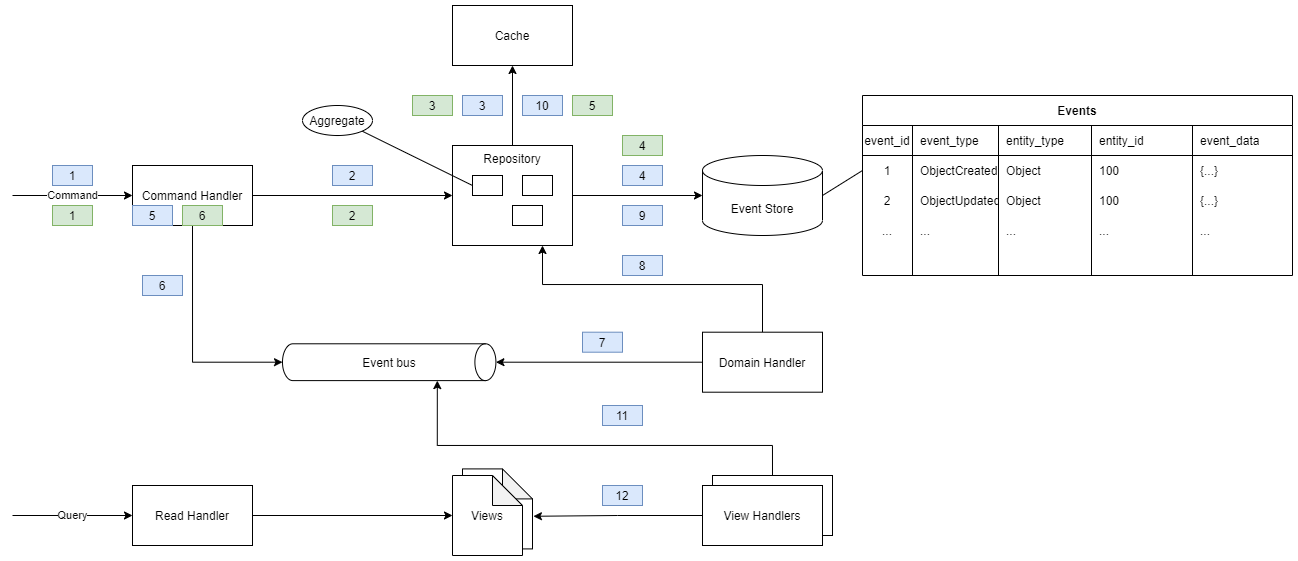
The blue squares represent the aggregate creation steps:
| # | Aggregate Creation steps | Notes |
| 1 | The command handler receives CreateObject command | |
| 2 | The command handler requests to the repository if the aggregate instance exists into the repository | An aggregate is a cluster of domain objects which are considered as one unit with regard to data changes. A transaction within an aggregate must remain atomic. |
| 3 | The domain repository checks if the aggregate instance is in the cache | not in cache |
| 4 | The domain repository checks if the aggregate instance is in the event store | nothing in Event Store |
| 5 | The command handler trigger the invariant verification | Aggregate enforces its own data consistency/integrity using invariants. In case of failure, throw back an exception indicating the business problem. |
| 6 | The command handler publish ObjectCreated event on the Event bus | This is an internal event bus. |
| 7 | The domain handler receives the ObjectCreated event from the Event bus | |
| 8 | The domain handler creates the aggregate instance from the aggregate root | |
| 9 | The ObjectCreated event is persisted into the Event store | |
| 10 | The cache is updated with the created aggregate instance | |
| 11 | The view handlers receives the ObjectCreated event | |
| 12 | The view handlers update their views |
The green squares represent the aggregate update steps:
| # | Aggregate Update steps | Notes |
| 1 | The command handler receives UpdateObject command | |
| 2 | The command handler requests to the repository to return the aggregate instance | |
| 3 | The repository check if the aggregate instance exists into the cache | if yes, go to step 6 |
| 4 | The repository triggers the rehydration process | compute the current state of the aggregate instance from the Event Store |
| 5 | The repository puts the rehydrated aggregate instance into the cache | |
| 6 | The aggregate instance is returned to command handler for invariant verification | then pursue since step 5 from Aggregate Creation steps |
Benefits:
Reliably publish domain events: events are reliably published whenever the aggregate state change (in event-sourcing, objects are built upon events versus events are generated by objects in a traditional way)
Provide an audit log and activity tracing log: all the events can store the identity for audit - they can be consumed by a specific handler to publish them (or part of them) on a message broker for external use
Preserves the history of the aggregate
Drawbacks:
Different programming model
Performance: when a domain object is built upon a huge number of events, there may be some performance issue - solution is to use snapshots (this issue is not present if domain objects are built on relatively small number of events)
Evolving events: schema of events may change over time - so the already stored events do not conform to the current schema any more - solution is to upgrade events to the latest version when they are loaded from the event store (upscaling)
Deleting data: you cannot delete data - solution is to do a soft-delete (emit a Deleted event)
If using a framework, this adds the framework dependency to the service's domain layer
Takeaway:
This pattern is suitable when there is a strong need of activity tracing (at domain object level) and a strong need of domain objects states investigations.
It is also suitable for domain objects that may have various state changes through their life-time.



